Numerous enterprises opt to deploy their mission-critical stateful applications on the Red Hat OpenShift platform. These applications come with imperative business requirements such as high availability, data security, disaster recovery, stringent performance SLAs, and operations across hybrid/multi-cloud environments. In this discussion, our focus will be directed towards one of these critical aspects.
This article delves into disaster recovery (DR), which is gaining prominence as a pressing concern in the Kubernetes community. This shift is driven by the platform’s increasing support for stateful applications, a departure from the predominantly stateless applications commonly deployed until now. The ultimate objective is to ensure seamless operations in the event of a datacenter, availability zone, or regional outage, thereby ensuring business continuity.
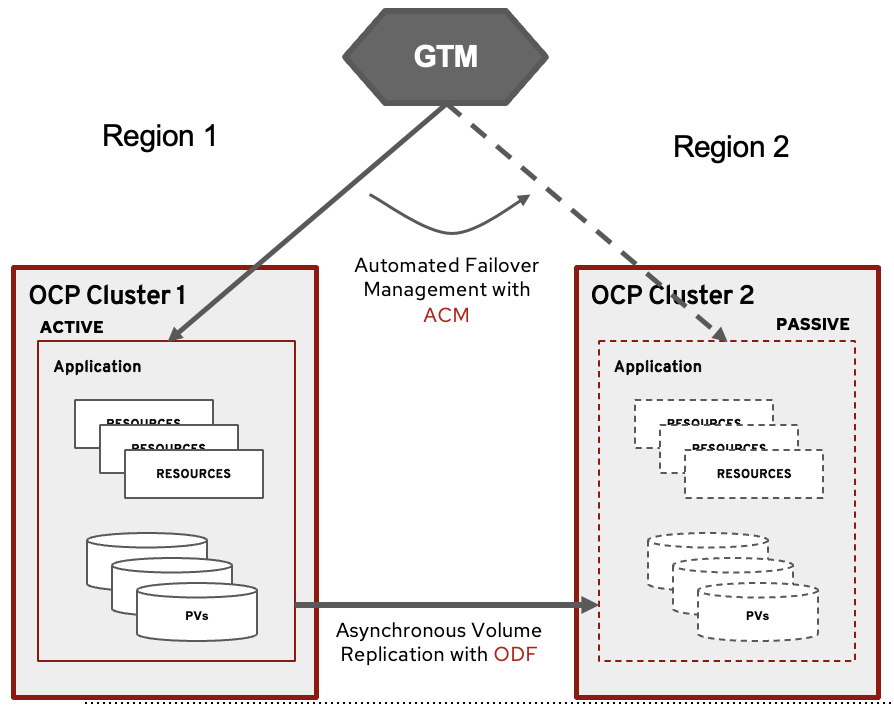
In alignment with this objective, OpenShift has expanded its disaster recovery solutions by introducing the Regional-DR solution. This solution is founded on two key OpenShift products: Cluster management facilitated by Red Hat Advanced Cluster Management (RHACM) and persistent data storage provided by Red Hat OpenShift Data Foundation (RHODF).
 Red Hat®
Red Hat® Microsoft Azure
Microsoft Azure